Next: 私の講義を受ける上で注意してほしいこと Up: コンピュータ内のデータその 2, 文字コード: 例として, Previous: ASCII コード表
Windows の日本語環境では, 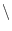 (バックスラッシュ)
のコードに対して¥記号を表示しています.
これはこの過去のしがらみ (JIS X 0201 1976)のためで,
実際には間違った表記となっています. 日本語以外の Windows では,
が表示されます.
また, JIS X 0201 1976 の前半 7bit 部分を Asciiコードと解説している
Webページも沢山存在しますが, それらも間違ったコード表記です.
(バックスラッシュ)
のコードに対して¥記号を表示しています.
これはこの過去のしがらみ (JIS X 0201 1976)のためで,
実際には間違った表記となっています. 日本語以外の Windows では,
が表示されます.
また, JIS X 0201 1976 の前半 7bit 部分を Asciiコードと解説している
Webページも沢山存在しますが, それらも間違ったコード表記です.
なお, コンピュータは, 上で述べた main frameのように, パーソナルでないものもあります. 過去には, 何種類かの日本語文字コードが, コンピュータシステム毎に存在していました. それらの中で, 代表的なもののひとつが, EUC (Extended Unix Code) です.
2024-04-26